Colby Imaging
Philosophy
While science deals with fundamental questions about our world and their answers, engineering addresses practical problems and their solutions. Nowhere is the synergism between these approaches clearer than as it relates to their application in medicine.
My training, interests, and career goals have gravitated towards this somewhat unique intersection of disciplines, and I believe that by focusing increasing effort at this junction, we can most effectively translate our research advancements into practical clinical progress towards the ultimate goal of alleviating human suffering and disease.
Research Focus
The human brain is one of the last true frontiers in science, and although fantastic progress has been made over the last century towards understanding how this remarkable organ functions in both health and disease, it is humbling to reflect on how much more there is still to uncover. Fortunately, because of a convergence of technological and theoretical advancements, and great public support, we are in the midst of an atmosphere that is ripe for discovery.
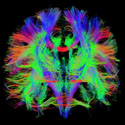 Specifically, my dissertation research involved several components: 1) The development of novel diffusion MRI analysis methodologies for investigating white matter connections in the brain (engineering), 2) Studying the relationship between white matter maturation in the frontal lobe and executive functioning advancements during typical development (neuroscience), and 3) Investigating the ways this relationship is affected in the context of fetal alcohol exposure (medical application). Feel free to look through my wiki for much more information on these works in progress.
Specifically, my dissertation research involved several components: 1) The development of novel diffusion MRI analysis methodologies for investigating white matter connections in the brain (engineering), 2) Studying the relationship between white matter maturation in the frontal lobe and executive functioning advancements during typical development (neuroscience), and 3) Investigating the ways this relationship is affected in the context of fetal alcohol exposure (medical application). Feel free to look through my wiki for much more information on these works in progress.
Bio
 I did my undergraduate training in Bioengineering at UC San Diego. One of the highlights was being awarded a Pacific Rim Experiences for Undergraduates (PRIME) fellowship through an institutional NSF grant for my proposal to develop a research collaboration between the UCSD Cardiac Mechanics Research Group, the San Diego Supercomputing Center (SDSC), and a high performance computing research group at Monash University in Australia. The collaboration that I started in 2004 is still in place, and continues to be a successful training opportunity for scientists and engineers, as well as a productive exchange between the laboratory groups.
I did my undergraduate training in Bioengineering at UC San Diego. One of the highlights was being awarded a Pacific Rim Experiences for Undergraduates (PRIME) fellowship through an institutional NSF grant for my proposal to develop a research collaboration between the UCSD Cardiac Mechanics Research Group, the San Diego Supercomputing Center (SDSC), and a high performance computing research group at Monash University in Australia. The collaboration that I started in 2004 is still in place, and continues to be a successful training opportunity for scientists and engineers, as well as a productive exchange between the laboratory groups.
After graduating in 2005, I took a position as an algorithms engineer with Science Applications International Corp. (SAIC). There, I was able to work on a great team of scientists and engineers as we came together to focus on a DARPA biodefense initiative to develop new ways to identify pathogens in complex environmental samples. The T.I.G.E.R. technology that we developed has been deployed to government labs, including the CDC, and is also being commercialized towards medical applications like epidemiological surveillance.
Currently, I am in the 8th year of my graduate studies in the Medical Scientist Training Program (MSTP) at UCLA. I am fortunate to have been able to participate in some terrific training opportunities that are in tune with my own philosophy of interdisciplinary collaboration and integration, including the Neuroengineering track in the Biomedical Engineering Interdepartmental Program, and the Neuroimaging Training Program (NITP) in the Semel Institute for Neuroscience and Behavior. My dissertation work was conducted in the Developmental Cognitive Neuroimaging Laboratory of Dr. Elizabeth Sowell.
Contact
John Colby, PhD Email
MD/PhD student
David Geffen School of Medicine at UCLA